



The Illusion of Training Load Quantification: What Really Matters
Optimization Won’t Fix a Flawed Paradigm.

Nowadays, coaches and scientists search for training load quantification models as if they were the Holy Grail of training—that one equation which, once optimized, will provide all the answers we need to train athletes effectively.
Thus, following the development of Bannister’s Impulse-Response Model, which introduced TRIMPs as a measure of training load, these models have been refined or adapted to different training zones (L-TRIMP), perceived effort (sRPE), power (CTL-TSS), etc.
All these models are based on the impulse-response theory. However, as the great Passfield and colleagues demonstrated in their famous 2022 paper, their development lacked scientific validity. A house of cards has been built upon these foundations, which are far from solid—quite the opposite.
In the future, we will see increasingly sophisticated algorithms based on this same principle—AI-driven models that take into account temperature, different exercise intensities, altitude, nutritional status, etc. Yet, they will continue to fail because they are based on a flawed theory or, at best, a highly limited one that only works in certain cases.
This is nothing new. Back in my penultimate year of university, around 2013, I designed an improved way to calculate TSS, considering multiple factors: intensity should have greater weight, time was not linear (2 hours in zone 3 is much harder than doing 1 hour one day and 1 hour the next), and extreme altitude and temperature deviations should be factored in (2 hours at 35°C should score higher than 2 hours at 20°C).
Perhaps I could have done well financially if I had continued in that direction, given our obsession with putting numbers on everything. However, I abandoned it for the reasons I will now explain—reasons that apply to all current and future load quantification metrics.
Problems
Attempting to measure the effect of a training program on an athlete based on load quantification metrics has several problems. Each of these issues alone is already severe enough to cast doubt on these measures, but when multiplied together, any resemblance to reality may be purely coincidental.
1. Estimating external load is a huge problem.
The first step in metrics like TSS, which is based on power, is assigning an external load score to training based on the power generated and the duration of effort.
This step is something we all take for granted, but in reality, it is extremely difficult. How do we quantify the effort an athlete has exerted?
We could use the total work done, which is simply the multiplication of power by time.
However, we know that physiologically, performing the same work in less time (with higher power or speed) is much harder. Thus, metrics like TSS modify the calculation by multiplying time by power squared, increasing the effect that power (intensity) has on the final result.
In TSS, power is calculated based on a percentage of the athlete’s FTP, called IF (Intensity Factor), which consists of dividing the session's power by the athlete’s FTP power. But broadly speaking, this doesn’t really matter, as it doesn’t change the calculation method: we could create a similar TSS based on another test, and the only difference would be that intensity would have a greater impact on the model.
TSS = time (in hours) * (Normalized Power / FTP)² * 100Since there is nothing magical about FTP or one-hour power, nor in squaring vs. cubing or raising it to the 10th power, we are essentially accepting—without validation—that squaring intensity (as a percentage of FTP) is the best way to quantify load, without comparing it to alternatives.
Moreover, we assume that normalized power (based on Coggan´s algorithm) is the best way to estimate the real physiological cost of maintaining an average power despite pacing variations, which is another huge topic in itself.
But well, I don’t want to dive into that in this article—I just want to highlight that, from the very beginning, we are making many assumptions that have no scientific basis but are still taken as valid.
And this is the least problematic part of these models!
2. The transition from external load to internal load is even more complex.
The same power or speed data can produce vastly different responses and fatigue levels depending on countless factors: previous fatigue, nutritional status, environmental stressors, etc.
For example: doing 5 minutes all-out followed by 55 minutes in zone 3 is much harder than doing 55 minutes in zone 3 first and then 5 minutes all-out. Previous fatigue makes the following effort take place under far greater stress. In the first scenario, we could spend the entire hour near our maximum oxygen consumption, while in the second case, we would only reach that level and accumulate fatigue in the last 3-4 minutes.
And of course, it goes without saying that we are not always training with full glycogen stores or in the same temperature conditions. In my region, for example, we notice a massive difference: doing 2 hours in zone 2 during summer can leave you with the same fatigue sensation as doing 4 hours in winter at the same intensity. But the TSS score is half.
There will be training load models that account for temperature or even allow inputting the athlete’s diet, but they will still fail in estimating how that temperature affects each individual and how this stress acts non-linearly (at first, you barely feel additional heat stress, but its impact grows over time, and after 3 hours, you may hit a critical point, leading to collapse or dehydration).
In short, up to this point, we might think that a good model won’t be reality, but it will at least resemble it closely. But now comes the real problem…
3. The same internal load generates a different adaptive response depending on your current state and timing (one workout makes you fitter, another destroys you).
Training load quantification models, as they are used today, assume that the body's response is predictable and proportional to the load. Not only is it not proportional, but it is also unpredictable, both in the magnitude of adaptation and in the type of adaptation.
The same workout that makes you fitter one week can make you worse another week. For example, numerous studies have shown an inverted U effect in high-intensity training. In most studies, after 6 to 8 weeks of doing 2 to 3 sessions per week, athletes stop improving (on average) and may even decline. Some hit this plateau much earlier, and some never improve—even in the first sessions.
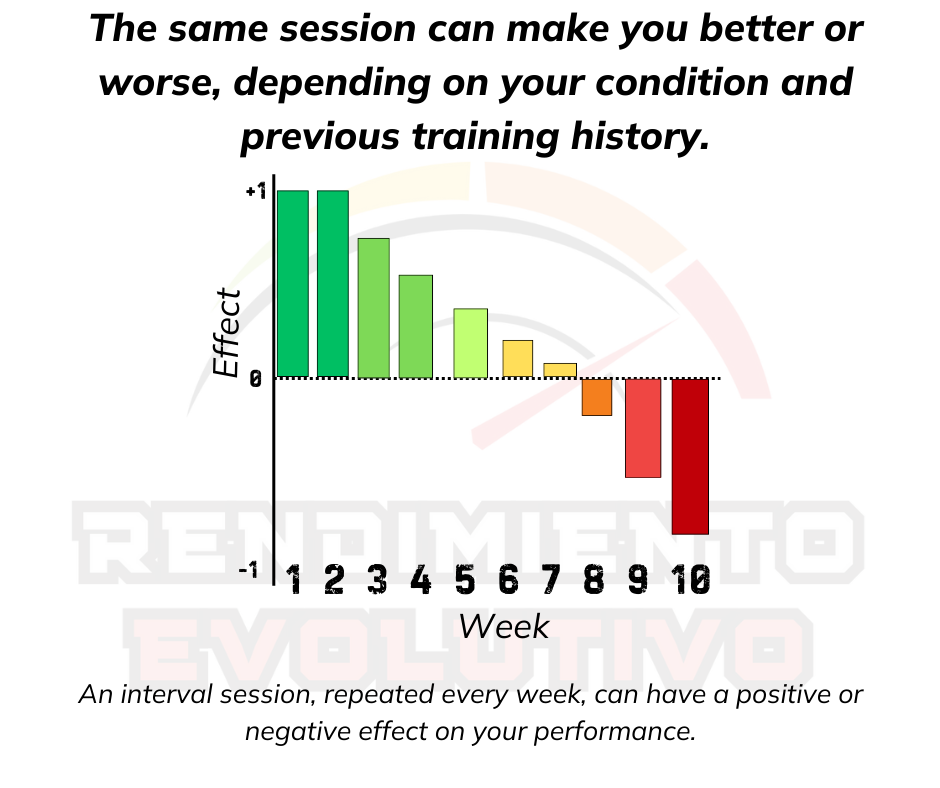
The way the body manages a disturbance can vary at any given moment. One factor, as I just mentioned, is the athlete’s prior training state or level of fatigue. But there are many more.
The body's adaptive capacity is limited, and it will tend to allocate it to the most critical aspects for short-term survival. A stressed, sick, inflamed, or injured athlete will not respond as well to stimuli, even if their training level remains the same.
Amateur athletes believe that these training load metrics accurately reflect reality because, for them, the effect of training is disproportionately high: they go from not training for months to suddenly starting a routine. Naturally, in amateur athletes, these metrics more or less correlate with improvement—but only because the effect of going from little training to a lot of training tends to be stronger than anything else.
In fact, some, without hesitation, refer to training load quantification metrics as “FITNESS,” as seen in Strava or Garmin. This use of language is even morally cuestionable…
Because while in athletes with clearly defined cycles of light and intense training there may be a correlation between training load and performance, in high-level athletes, this correlation is usually absent. People who train seriously year-round will not see a clear relationship between increases or decreases in their CTL or any other metric they use and their performance—because the impact of load is minimal.
CTL = weighted average TSS from the last 42 days, used to determine training load.
Why 42 days? Divine inspiration.4. The same stimulus generates different adaptations.
A final aspect, closely related to the previous one, is that even in cases of performance improvement or decline, we cannot fully control the body's adaptive responses.
Training at VO2max pace won’t necessarily improve your VO2max, just as going to altitude won’t necessarily improve your red blood cell count. Organisms adapt through a self-organizing process, meaning they simply explore new ways to adjust to the environment and stabilize those that are “good enough,” without following a structured manual that can be repeated across different athletes (I explain this in more detail in my book).
If this concept is difficult to grasp, just think about the Black Box Model, which I’ve seen referenced in many places, though I’m not sure who originally developed it.
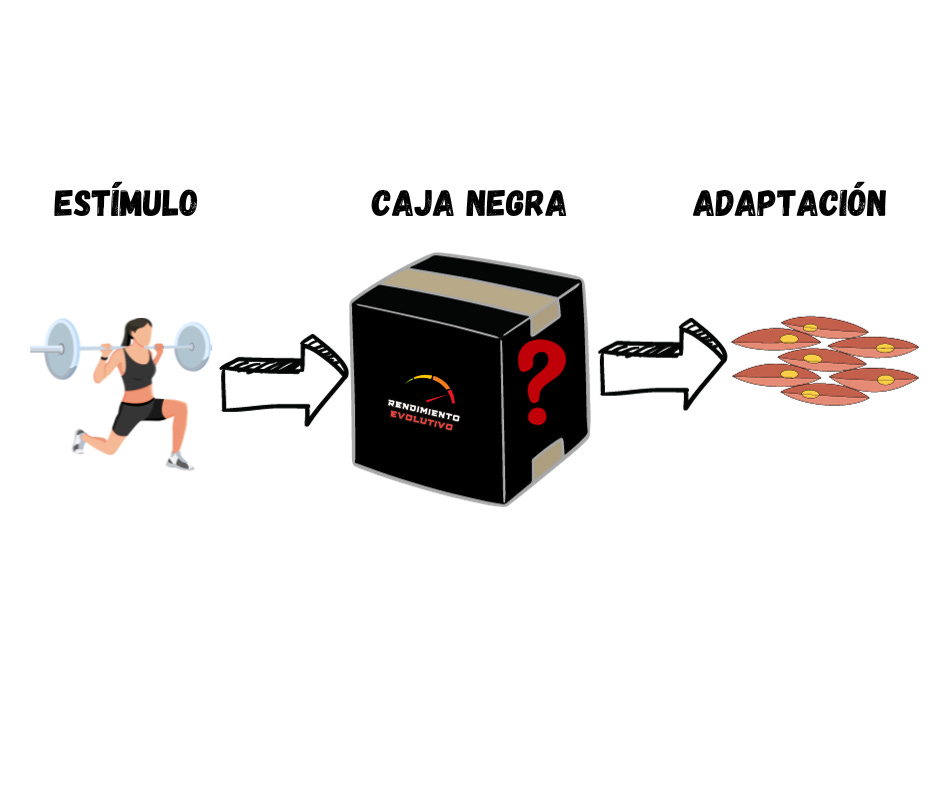
(Black box = caja negra; adaptation = adaptación).
In the training process, the only thing that the athlete or coach can control is the stimulus we generate. This stimulus is endured by the body, which will produce a series of reactive responses that are more or less expected (sweating, increased body temperature, heart rate, blood pressure, etc.), as well as a series of predictive adaptations to future loads that aim to adjust to these stimuli—but in ways we cannot predict.
Broadly speaking, this means we cannot control adaptations, only the stimuli.
Paraphrasing the famous article by John Kiely:
The same training program can lead to very different adaptations; and different training programs can lead to similar adaptations.
WHAT MATTERS
Thinking of the body as a black box might feel overwhelming, as it can make us feel lost. But we can also see it as something positive: WE ARE NO LONGER LIMITED BY MECHANISTIC THEORIES.
Now we are free to do something new, something better.
We can design different training approaches to achieve the same goal. Workouts that are more enjoyable, better suited to the terrain where we train, or aligned with what we like. We no longer need to obsess over hitting a weekly TSS target—we can now focus on what truly matters.
Training load metrics placed the emphasis on the training plan. They analyzed and measured the program. But the program does not matter. Different champions reach success with different training plans. And the same champion does it with different coaches and different training methods.
If the program were so crucial, we could simply copy a champion’s plan, adapt it to an athlete’s level, and replicate it. But this doesn’t work.
In reality, the training program doesn’t matter—what matters is WHAT EFFECT THE TRAINING HAS ON YOUR BODY. That is what’s truly relevant.
I don’t care if this week you accumulated 50 TSS less than last week. Last week you were fresh, and this week you’re feeling exhausted. Last month, with 120 CTL, you were flying, and this month, with the same load, you feel more strain when pushing the same watts.
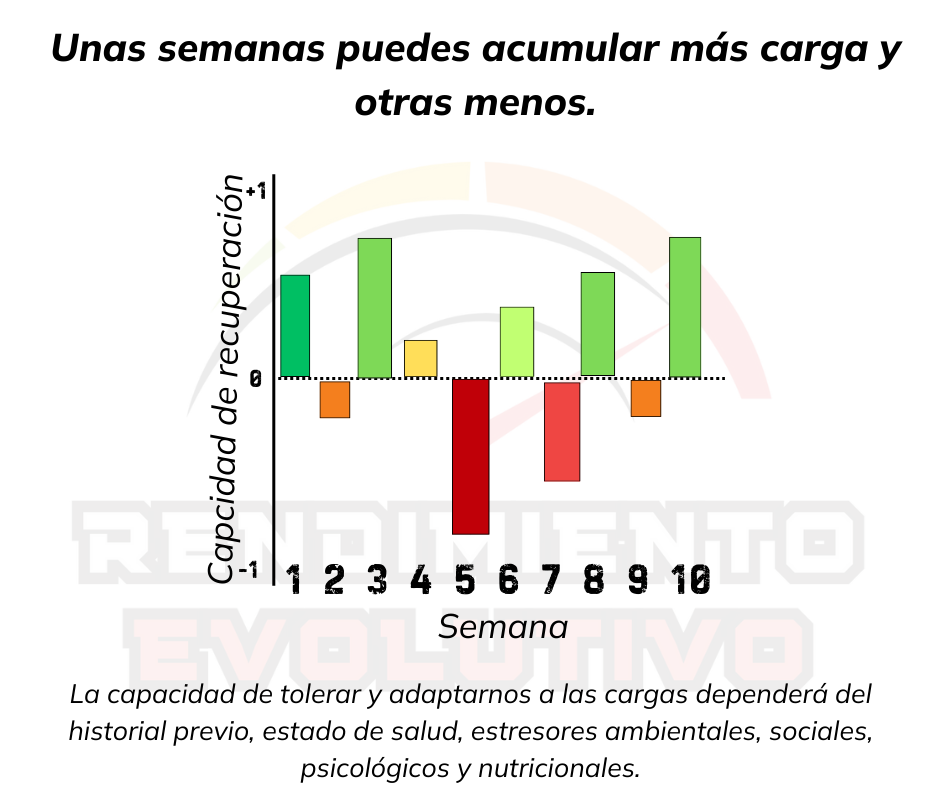
"Some weeks you can accumulate more load, and other weeks less. Your ability to tolerate and adapt to training loads will depend on your prior history, health status, environmental, social, psychological, and nutritional stressors."
See?
I’m not saying you don’t need to measure training load—I’m saying it’s not relevant.
You only need to measure two things:
Your fatigue-recovery state: Whether you are training more, less, or about the same as what you can tolerate—and by how much.
Your performance progression: Whether you are improving, declining, or maintaining in the three main performance qualities:
Endurance (aka, aerobic)
High-intensity (aka, anaerobic)
Maximum strength or power
With just these two factors, we could already build a map of what’s happening and decide how to act at the session, microcycle, or macrocycle level.
We could go infinitely deeper into these two aspects, but that’s too much for today´s article. Today, I just want you to remember that what matters is not the training program itself, but the effect it has on you—and that by measuring the program instead of the effect, we will hardly get an accurate picture of what’s happening.
No matter how much we optimize the algorithms, this will not improve prediction, because they are based on a flawed principle (the direct and predictable relationship between training and adaptation).
PS: If you want to know more about the foundation of training adaptation, I wrote my book.
See you next time.
This is a fantastic article and you communicate the principles very well. Unfortunately Training Peaks is the hub most of us coaches use and thus it blasts the athletes (and the coach) with TSS, CTL, ATL, ect. I don't bring it up with my athletes so thankfully they don't get fixated on it.
cannot agree more.